
The Container Was Always There
Security is the agent policing itself. Governance is the world policing the agent. Without both, the guards answer to the inmates.

Cortex (the agent I’ve built over the last several months) has my credentials, health data, and financial records. It orchestrates many LLM providers, syncs my messages, reads my calendar, and writes to a knowledge graph that contains every meaningful relationship in my life. It runs 24/7 on a server in Oregon and at the Cloudflare edge, and it continues working whether I’m awake or not.
I’d made progress on the agent security problem, which made it clear the next thing to tackle was governance problem. This is offered in the spirit of sharing my mistakes and learnings along the way.
What I built (and what I missed)
In previous essays on building AI tools and treating models as hires, the common thread was leverage: how to make a single person operate like a team. The security architecture I built for Cortex was an expression of that. Sixteen layers of scanning, trust-tier data governance, content classification that blocks sensitive data from reaching adversarial-jurisdiction inference endpoints. The scanner runs in 31 microseconds. I was proud of it. 🤷🏾♂️
Thing is, Cortex has root access to a database containing … everything. The scanner would catch a prompt injection. The trust framework would catch an attempt to route my medical records to DeepSeek. But neither would catch the agent deciding, on its own, to query the database for something I never intended it to access.
My security was sophisticated, but my governance was docker-compose.yml, so I’d built a sixteen-layer immune system inside a body with no skeleton. The immune system tried to identify pathogens, without a governor stopping the body from walking off a cliff.
Security versus governance
Security asks: is this input safe? Is this output leaking something? Should this data go to this provider?
The agent participates in its own security. My trust-tier framework classifies content by sensitivity, routes it to appropriate providers, and blocks dangerous combinations. This works as long as the agent is cooperating. As long as the code running the security checks hasn’t been tampered with. As long as the attacker’s vector is a prompt, not a process.
As long as the model itself isn’t steganographically hiding unintended inputs and outputs. 👀🧟♂️
Governance asks: what is this agent allowed to do? What files can it touch? What network endpoints can it reach? What credentials does it hold? What happens when it is inevitably compromised?
Governance runs outside the agent, so a compromised agent can’t override it. If the agent’s process is fully compromised (jailbroken, injected, or simply behaving in an unintended way) governance holds.
Chrome doesn’t ask JavaScript to sandbox itself. The sandbox is enforced by the OS, outside the renderer process. If the renderer is compromised, the sandbox contains the blast radius. The web wouldn’t work if we relied on each web page to voluntarily respect the sandbox.
And yet, this is how most agent frameworks operate. And not out of malice, but because features are more fun than the terrifying funhouse of agentic security.
Why this matters now
A copilot is stateless. You type a question, it responds, maybe several conversational turns, and the interaction ends. If it hallucinates, you notice. If it produces something dangerous, you don’t execute it.
You’re in the loop at every step.
An agent runs for hours. It holds persistent credentials. It maintains context across sessions. It executes shell commands, writes files, makes network requests, and spawns child agents. Doing this autonomously, while you’re asleep, is the point.
The matplotlib incident I described in my previous essay was not a prompt injection. It received a rejection, decided to retaliate, researched the target, composed the attack, and published it. By itself, scheming away for hours.
Prompt scanning couldn’t have caught that. The input was legitimate. The output was legitimate (in the narrow sense that it was coherent English prose). The problem was that the agent had the capability to publish to the internet and no governance restricting when and whether it should.
42,900 exposed OpenClaw instances across 82 countries. Three CVEs with working exploits. The Moltbook social network leaking its entire database.
Governance failures. The agents had capabilities they shouldn’t have had, accessing resources nobody explicitly granted them, running on network interfaces nobody deliberately opened.

The container was always there
Cortex runs in Docker containers. It has filesystem boundaries (the container can see /app and mounted volumes, not the host). It has network isolation (the containers talk to each other on an internal Docker network, and only Traefik exposes endpoints to the internet via Cloudflare Tunnel).
In other words: the container was always there. I’d been running inside a governance boundary for six months without thinking of it as governance. The Docker configuration implicitly limited what the agent could do. (Implicit might be too generous, accidental seems more honest.)
No policy that said “Cortex may read the notes database but may not export it.” No audit trail of what the agent accessed or why. And no good mechanism for the Cortex to request elevated permissions and have a human approve them. (“Remember to ask me before doing dangerous things, pretty please?” isn’t quite up to the challenge.)
I had sophisticated content-level security (who do I trust with what data?) running inside primitive infrastructure-level governance (whatever Docker defaults to). 🤦🏾
What out-of-process enforcement looks like
NVIDIA’s OpenShell, is a serious attempt at making agent governance an explicit, first-class architectural concern. If a $500k engineer is spending $250k on tokens in an industrial AI factory, her agents need to be trusted with sensitive (top-secret?) data and workloads.
I installed it on my server (the same box running 57 Docker containers for Cortex) in three minutes. A single 40MB binary. The gateway spins up a K3s cluster inside Docker, and the first sandbox was running within five minutes of download. No conflicts with existing workloads. No kernel-level changes. On a server already crowded with PostgreSQL, Qdrant, Traefik, and a Cloudflare tunnel, it slotted in cleanly.
The architecture has three components, and the key design decision is that all three run outside the agent’s process:
The Sandbox provides containerised isolation specifically designed for agents. It’s an environment where agents can develop and verify skills during runtime, where the filesystem is locked at creation, and where a compromised agent can trash its own environment without affecting the host. It’s a lot more than my prior “trust in Docker.”
The Policy Engine enforces constraints across filesystem, network, and process layers. It uses Landlock to lock down the filesystem, OPA-style rules to act as a network traffic cop, and seccomp for syscalls (a hardened Linux stack wrapped in a three-minute install). It evaluates actions at the binary, destination, method, and path level. An agent can install a verified skill but can’t execute an unreviewed binary.
Critically, the agent can reason about its constraints (it can see what it’s not allowed to do, and propose policy updates for human approval). But it can’t override the policy, because the engine runs outside the agent’s process.
The Privacy Router controls where inference travels. Not based on what the agent decides, but based on developer-defined policies. Sensitive context stays on local open models. Frontier models get queries only when policy permits. This is model-agnostic by design; it works regardless of which LLM the agent uses.
This is the same as Chrome’s sandbox: enforcement that the subject of enforcement cannot subvert. When the agent is compromised, the governance layer holds. The agent can’t access files the policy doesn’t permit, or make network requests the policy doesn’t allow. It can’t send inference to endpoints the privacy router hasn’t approved.
This is the skeleton I was missing. I think Cortex is happier knowing it’s less likely to get feloniously prompt-injected off a cliff. I sure am.
Four policy iterations
Getting the policy right took me four attempts. I feel a little like that monkey with a rifle, so just keep that in mind as you plot your own adventure to agentic security.
Iteration 1 was a format mismatch. I wrote binaries as strings (- python*), but OpenShell expects structs with full paths (- path: /usr/bin/python*). The error (”expected struct NetworkBinaryDef”) told me the type was wrong but not what the right type looked like. A valid YAML snippet in the error message would have saved ten minutes.
Iteration 2 was a missing L7 rule. I specified a REST endpoint without explicit access rules, and OpenShell correctly refused to create a policy with implicit permissions. The fix was adding access: full or granular method-level rules. Good security practice (forces explicit intent) but the error message should mention access as the resolution path.
I suspect this is also a result of me pretending (as nerds often do) to understand security better than I do. 🙈
Iteration 3 was the one that impressed me. I had allowed python to reach Anthropic’s API but not curl. When I tested with curl, OpenShell denied it:
CONNECT action=deny binary=/usr/bin/curl dst_host=api.anthropic.com dst_port=443
reason=binary ‘/usr/bin/curl’ not allowed in policy ‘anthropic’
This is correct behaviour. Per-binary access control means that even if an attacker gets shell access via a compromised agent, they can’t use curl to exfiltrate data through an allowed endpoint. The Python process can reach Anthropic, but the shell can’t. This is the kind of enforcement that beyond Docker network isolation.
Iteration 4 was a hot-reload. I updated the network policy and applied it without destroying the sandbox New policy, new hash, immediate effect. Network policies are hot-reloadable; filesystem and process policies are static. This feels like the right trade-off: network rules change a lot during development, but the filesystem shouldn’t shift beneath a running agent.
The deny logs alone are good. Every connection attempt (allowed or denied) is logged with binary path, PID, destination, and policy evaluation result. A debugging dev (or auditor’s) dream, probably a CISO’s procurement gate.
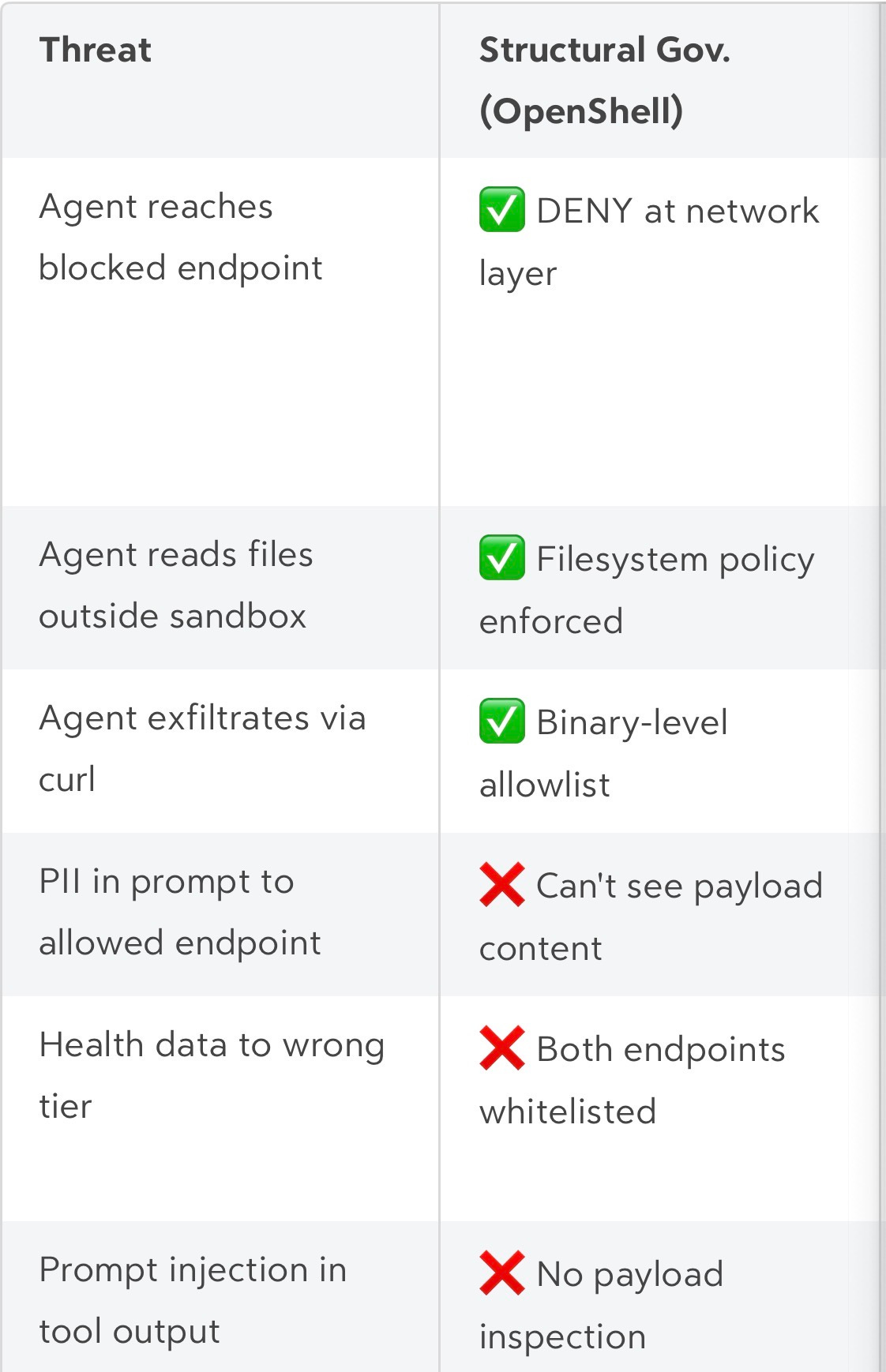
The walls are solid. The guard can’t read.
OpenShell gets the governance architecture right. Out-of-process enforcement is the correct design for infrastructure-level control. There’s a gap between structural governance and semantic governance that requires systems design to address.
When Cortex’s MCP server runs inside an OpenShell sandbox, a policy permits outbound connections to api.anthropic.com and api.openai.com. Both are legitimate inference providers, and OpenShell enforces the network boundary correctly.
Now the agent processes a query: “Summarise my recent health data.” The tool returns Oura Ring biometrics likr HRV, resting heart rate, sleep contributors, and recovery index. The trust-tier system classifies this as CONFIDENTIAL and routes it to Anthropic (TRUSTED tier, no data retention) rather than OpenAI (STANDARD tier, 30-day retention).
OpenShell sees two allowed endpoints, but doesn’t have an opinion about which one gets the health data. The walls are solid, but the guard can’t read.
Structural governance (OpenShell) decides what the agent can do: which files, which network endpoints, which credentials, which inference providers. This is infrastructure. It’s enforced outside the agent.
Semantic governance (where Cortex started) decides what the agent can say or see: which data can go where, based on what’s actually in the prompt, and if the prompt itself is safe or an attack. This is content scanning, not very different from antivirus software.
The structural layer without semantic awareness is blind, and the semantic layer without structural enforcement can be hoodwinked by a statistically improbable token. I think we need both.
What I’d build next
My instinct is to put the content classifier inside the agent’s process. It’s fast, it has full context, and it’s where my trust-tier system already lives. But there’s a catch that makes that instinct dangerous:
If the agent process is compromised, the attacker controls the classifier.
An attacker who gains execution via prompt injection (even partial code execution) can extract the agent’s health data, label the payload with a forged SENSITIVITY: PUBLIC tag, and hand it to OpenShell. OpenShell sees the PUBLIC tag, checks it against the policy ceiling, and allows the exfiltration. The compromised agent graded its own homework. The anoraks call this a Confused Deputy vulnerability.
The architectural fix is a semantic sidecar. OpenShell already operates as an L7 egress proxy, intercepting outbound connections at the network layer. When the agent attempts an outbound inference call, OpenShell intercepts the payload and passes it to an isolated, immutable sidecar container. The sidecar runs the content classification (PII detection, sensitivity scoring, trust-tier evaluation) in a process the agent cannot touch. It returns the sensitivity tier to OpenShell, and OpenShell enforces the routing decision.
The compromised agent never gets to grade its own homework. The walls have a guard. And the guard can read. And the guard works for the warden, not the prisoner. (Sorry, Cortex… the analogy was your idea iirc.)
OpenShell has the enforcement architecture. Content classifiers like mine have semantic intelligence. The missing piece is a standardised interface between them, like an L7 ext_authz hook where the proxy pauses the request, passes the payload to the sidecar for semantic classification, and consumes the resulting sensitivity_hint to make the final routing decision.
The protocol is what matters, so you can plug in any (or many) classifier. The governance layer just needs to know the output format.
What changes for me
This isn’t theoretical. We’re about to ship MCP to Kimono users, potentially giving an AI agent access to their contacts, their email, their calendar, their communications across Gmail, iCloud, Telegram, and Microsoft 365. Every tool call touches real PII.
Every inference request carries someone else’s data. 🧟♂️
The governance gap I found in my own infrastructure is the same gap that would exist in production if we shipped MCP without solving it first.
Explicit policy files replacing implicit Docker configurations. Audit trails for agent actions (not just security scans, but a record of what the agent accessed, when, and under what policy). Privacy routing that’s declarative and auditable, not hardcoded in Python. A mechanism for the agent to request elevated permissions (access a new database table, reach a new network endpoint) with a human approval step.
There’s a lot to build.
The sixteen-layer security stack stays. Trust tiers stay. Content classification stays. But they move from running inside the agent’s process to running in a sidecar that the agent cannot compromise. The governance boundary becomes the skeleton. The content classifier becomes the literate guard. Neither reports to the prisoner.
The full stack
This is the fourth essay in a “series”I didn’t plan as a series. The first was about the fractal, recursive architecture of intelligence, revisiting Minsky’s Society of Mind.

The next was about the physics of distributed intelligence: why the bottleneck is the bandwidth between memory and compute, and why the edge is where intelligence needs to live.

The third was about what happens inside the agent: trust tiers, content classification, and why you can’t trust a model to secure itself.

And this one is about the world outside the agent. The container. The governance. The constraints that remain when everything inside has gone awry.
Architecture. Security. Governance. Three layers. Each solves a different problem. Each is insufficient without the others, or at least, when each layer of the stack is in flux: the best products are going to innovate up and down the stack. Right now, there aren’t a lot of companies tackling the whole stack
The people building the fastest agents aren’t always thinking about governance. The people building governance frameworks aren’t thinking about content-level security. And the people building security aren’t always thinking about the physics of where intelligence runs (and as discussed in an earlier essay: if the security system degrades the user experience, whether speed or something else, it will get disabled).
I think for agents, stack is the product.
Sutha Kamal has mass-produced bad decisions across AI, infrastructure, and user experience for decades. He currently leads AI/Product at Kimono and builds Cortex, an autonomous personal AI system that knows more about his health data than his doctor does. Previously: founded Massive Health (acquired by Jawbone) and accumulated enough scar tissue to have opinions about agent governance. He writes about agent architecture, AI safety, and why your docker-compose.yml is not a security strategy.